Supervised Neuroevolution¶
Supervised Neuroevolution is the application of Neuroevolution to supervised learning. Typically, a supervised learning setting has a set of example inputs \(X = x_1 \dots x_N\) and a set of example outputs \(Y = y_1 \dots y_n\) and the objective is to find a function \(f\) that minimizes a well-defined loss function \(L\) across the dataset \((X, Y)\):
In Supervised Neuroevolution, \(f\) is a neural network which is optimized via neuroevolution.
Overview of SupervisedNE¶
EvoTorch provides direct support for Supervised Neuroevolution throough the SupervisedNE class. Consider a dataset, \(N=100\), generated from the function \(y = x_1 + x_2\) by sampling \(x_1, x_2\) from the standard normal distribution:
This can be wrapped up as a torch.utils.data.TensorDataset instance for convenience:
Creating a SupervisedNE instance for this dataset is straightforward:
from evotorch.neuroevolution import SupervisedNE
sum_of_problem = SupervisedNE(
dataset=train_dataset, # Use the training dataset generated earlier
network=nn.Sequential(nn.Linear(2, 32), nn.ReLU(), nn.Linear(32, 1)), # Simple MLP
minibatch_size=32, # Solutions will be evaluated on minibatches of size 32
loss_func=nn.MSELoss(), # Solutions will be evaluated using MSELoss
)
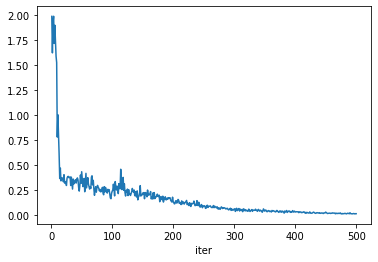
Then each network evaluated by sum_of_problem will be assigned a fitness based on how well it minimizes MSELoss on a 32 samples drawn from the train_dataset. Training the simple MLP will show a clear progress::
from evotorch.algorithms import SNES
from evotorch.logging import PandasLogger
searcher = SNES(sum_of_problem, popsize=50, radius_init=2.25)
logger = PandasLogger(searcher)
searcher.run(500)
logger.to_dataframe().mean_eval.plot()
Output
Unless your data is incompatible with torch.utils.data.DataLoader and/or the notation that minibatches drawn from the dataloader consist of data and targets:
then SupervisedNE should work in most cases. If not, then you can create custom functionality wherever you see fit:
class CustomSupervisedNE(SupervisedNE):
def _make_dataloader(self) -> DataLoader:
# Override to generate a custom dataloader
...
def _loss(self, y_hat: Any, y: Any) -> Union[float, torch.Tensor]:
# Override to define a custom loss function on network output yhat vs. target output y
...
def _evaluate_using_minibatch(
self, network: nn.Module, batch: Any
) -> Union[float, torch.Tensor]:
# Override to modify how a network is evaluated on a minibatch
...
def _evaluate_network(self, network: nn.Module) -> torch.Tensor:
# Override to completely change how a network is evaluated
...
Manipulating Minibatches¶
SupervisedNE includes some particular features to manipulate how networks are evaluated on minibatches. These are:
minibatch_size: int, which defines the size of the minibatch that each network is evaluated on. This argument is passed as thebatch_sizewhen theSupervsiedNEinstance instantiates it's dataloader.num_minibatches: int, which defines the number of minibatches that each network is evaluated on. Each minibatch will have sizeminibatch_size. This argument is useful in conjunction withminibatch_size, for example, when theloss_funcis a non-linear function of theminibatch_size, or the GPU memory does not permit a largerminibatch_size, or some other reason thatminibatch_sizemust take a particular value. In any of these cases, settingnum_minibatches > 1allows you to repeatedly evaluate each network on different minibatches, with the overall loss (fitness) averaged across the minibatches.common_minibatch: bool, which specifies whether the same minibatch(es) should be used to evaluate all solutions when a SolutionBatch instance is passed to the SupervisedNE instance'sevaluatemethod. As noted in recent work, it is sometimes more effective to evaluate all solutions on the same sets of minibatches, as this may reduce noise, for example, when approximating gradients in distribution-based evolution strategies. This is particularly true whencommon_minibatch = Trueis used in conjunction withnum_actors > 1, as each actor will evaluate it's sub-population on it's own fixed set of minibatches.
For example:
minibatch_size = 16, num_minibatches = 2, common_minibatch = Falsewill mean that each network is evaluated on it's own set of 2 minibatches of size 16, with the loss averaged across these 2 minibatches.minibatch_size = 64, num_minibatches = 1, common_minibatch = True, will mean that every network described by a SolutionBatch passed to theevaluatemethod will be evaluated on the same minibatch of size 16.minibatch_size = 4, num_minibatches = 8, common_minibatch = True, num_actors = 16, will mean that there will be 16 actors, each of which will evaluate a sub-population of the SolutionBatch passed to theevaluatemethod. Each of the 16 actors will generate 8 minibatches of size 4, and will use those 8 minibatches to evaluate all of the solutions in its assigned sub-population.